
图像多标签识别
撰写于 2020-10-29 修改于 2021-07-07 views
[TOC]
ToB中的图像多标签识别
一、概述
定义问题
这个Tob项目到底是什么?
现实生活中,人们通常会使用手机拍摄保存自己所看所闻的场景。因此,对相册中的照片场景及相关进行识别分类,帮助人们更快速整理照片成了一种不可或缺的需求。
拍摄的画面,到底包含了什么,又属于怎样的场景?就是图像多标签项目想要做的事。

标签都有什么?标签的特性?
标签
根据相册中经常出现的画面选定了上百个标签,概括一下主要分为八大类标签,例如 :
人物:成人,合影等
动物:猫,狗等,包含长尾标签,例如具体的贵宾犬、苏格兰折耳猫等
场景:超市、办公室、建筑等
……
标签特性
这批标签存在以下四非,是问题最大难点所在。
标签
非体系化:即层级关系,存在大类和细分类并存情况。例如:猫和苏格兰折耳猫。标签
非原子性:类别可能涵盖的形式种类繁多。例如唱歌的形式多种多样,单人站立唱歌,多人站立唱歌,多人带动作唱歌等标签
非独立性:即相关关系,存在两个类别既不互斥也不完全相同的情况。例如绘画和卡通,如果绘画恰巧是卡通人物,则也属于卡通,但是并不是所有的卡通都属于绘画。标签
非单一性:即因果关系,存在有一必有二的情况。例如照片中存在森林和丛林,必然存在树。
一个CV项目的完成,依靠的是数据、算法、推理三块能力,接下来也会按照这个顺序来依次做详细的介绍。
本节首先展示总结梳理的思维导图,便于读者对项目有整体的把握。
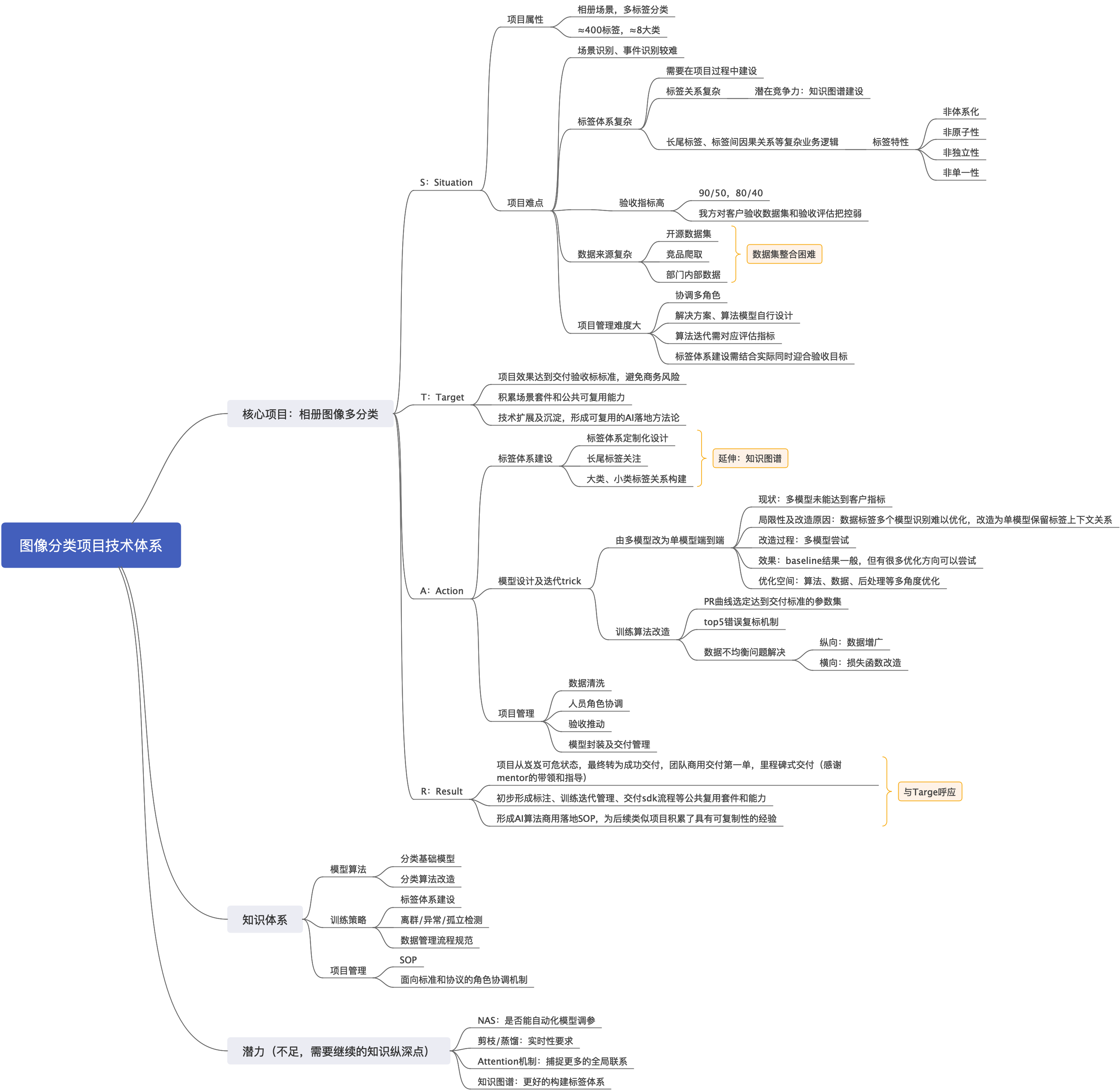
二、数据集构造
数据管理
数据集初始化
为了保证数据集的完整性及多样性,主要从以下三个方面构建项目数据集。
公开数据集
open-images v5 [1]
Open images 数据集是Google提出的数据集,在OID-dataset中详细的介绍了数据集的基本信息,不仅如此,OID-paper中还详细地从数据集构造、数据如何标注、模型训练及测评等多个角度进行了介绍。由于数据全部来自Flickr,因此更符合真实场景。涵盖8000+类别及900w数据的多标签数据集,作为项目数据集初始化很适合,而且论文中的方法和经验也有很多值得借鉴的地方。
- 标签映射:将OID数据集标签翻译并选择合适标签映射到项目标签
- 数据集构建:按照映射,选择人工标注过的相应数据
爬取数据
公开数据集缺陷
由于项目背景是国内场景,OID数据集存在以下两种情况的缺陷:
- 国外不存在一些场景,例如文档类;
- 场景虽满足但是全部为国外,存在覆盖度不足的情况,例如餐厅、博物馆等
- 长尾标签数量较少,例如猫狗细分类
以上三种情况,都需要爬取一定的数据做补充。
客户定义覆盖度
在和客户合作中,迭代模型输出测试结果发现,有些标签其定义范围比我们自有情况更大,客户会提供少量示例图集,因此也需要爬取数据增大标签覆盖度。
内部积累数据
部门和公司其他内部合作积累的数据,更符合国内的场景,这部分数据也做相应的标签映射,用于构造数据集。
主要有以下两种方式(通过内部工具):
- 关键字爬取:输入标签名直接进行爬取,并且由标注人员核验数据是否符合
- 以图搜图式爬取:搜图,直接上传示例图片,标注人员将搜索结果中符合示例图片的数据爬取保存
至此,数据集初始化完成,数据量大概在90w的量级,每个数据的标签量在4个左右。
但是数据集仍然存在很多问题,具体在之后的数据集模块及算法模块详细阐述。
数据集清洗
一个大数量级的数据集通常存在两个问题,一个是漏标签,一个是错标注。
项目中的数据也存在这样的情况,而如何做数据清洗去解决这些问题,是改善模型的一个基本关键之一。
而面对庞大的数据量,kaiming [3] 也曾在论文中提到过,当一个标签的数据量达到某个边界时,其错标或漏标对整个模型表现的影响几乎为0,因此,数据集清洗的流程是要建立在模型已有结果的基础上的。
这里先假设已有baseline及相应的测评结果,便可剔除超出临界点的标签,将清洗工作专注在部分标签上。
针对这两种情况,清洗的方法一致:
提取数据
以标签为单位,提取该标签下的所有数据。
构建伪标签
对于每一个数据,它的标签主要可分成如下几种形式:
数据本身的标签
baseline模型预测结果top5中高于0.5阈值的标签
竞品(主要是百度图像识别API)预测结果映射到项目标签
清洗
- 标注标准:细化并撰写标注文档,指定文档格式,重点对每个标签特有属性进行定义及区分,指导标注人员提高关注点
- 标注可视化:每天随机可视化标注结果,抽检并对理解不当标注做强调,将标注准确率控制在90%左右
- 更新数据集标注
数据集划分
以标签为基本单位,按照9:1划分为训练和验证集,验证集即为自有测试集,用于迭代交付中指标的核验。
三、解决思路
解决问题
算法模型
初期尝试
在接手这个项目时,之前的同事已经做了一种方案,即
将标签具体分为12个类目,训练相应的小模型,之后再合并到一起推理出结果。
这种分治的思想不够适用,是因为标签本身的特性导致的,因此同事也提到迭代优化难的问题。
确定路线
调研了一些图像多标签的论文及实际应用场景,发现很少会有类似的落地项目,大多是在学术的层面进行探讨,或者是nlp项目通过BERT等方式做多标签。
因此,对于这个项目而言,可以借鉴的成熟经验比较少。如何入手,如何做好冷启动是一个问题。
本着less is more的原则,以及对OID论文的研读,决定baseline先采用如下策略:
- 模型backbone选择resnet [2],该结构在ImageNet2015中大放异彩,其优越的收敛速度以及优化性能(模型速度和精度的平衡)是可以保障模型基本需求
- 多标签训练策略通常是将每一个输出神经元都看成一个单独的二分类问题,因此损失函数首先想到二分交叉熵[4]
- 端到端训练,多机多卡提升速度
具体使用什么模型,可以先尝试几种常见的竞赛及论文中提到的模型,再对比所需推理速度和精度,权衡选择backbone。
模型选定后,训练出baseline,根据测评结果和交付反馈决定优化方向。
训练优化
训练及收敛
这里提到的都是一些常见的训练优化策略,可以把这些策略看成是一个个小的部件,但是如何组合及使用这些部件才能达到最好的效果,还是需要一些ablation study验证。
题外话:做好一个项目的管理,包含了回归测试的维护,对于每个版本的模型迭代策略做好记录,消融学习能够有效的找到最佳超参。
Learning rate warmup
训练初期,网络所有的参数都是随机初始化,和最终参数值相差甚远。如果初期使用太大的学习率可能会导致数值不稳定。因此,使用warmup策略,使学习率在若干epoch内由0线性增长到设置的数值,这种方式训练会更加鲁棒。[6]
Pretrain model
利用已有的预训练模型,将大型数据集上训练好的已有模型知识迁移,帮助模型训练。[7] [8]
Cosine learning rate decay
训练过程中的学习率调整是非常重要的。和warmup相配合,能够达到更好的收敛效果,具体做法是将学习率从指定数值按照coseine的方式降到0。[6] 假设总批次数为T,那么当训练到第t个批次时,学习率应该是
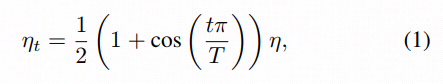
Multistep learning rate decay
这是一种常见的学习率线性衰减策略,根据其衰减策略也能看出,它很适用于后期模型微调时修改学习率,而且在整个模型已经处于收敛较好的情况下,即最优解附近,优化个别标签时学习率变化骤降,小步伐抵达最优解很有效。
数据不均衡
数据不均衡是一种很常见的现象,现实生活中这些标签的分布也是呈现某些标签较多,而其他标签只是偶尔出现或者长尾的现象。
但是对于神经网络来说,训练时如果数据不平衡,无论从算法本身对数据分布要求的角度,还是从损失函数的构建角度,都会对深度模型学习造成严重的影响。[9]
上述原因提供了解决的依据,我们从横向和纵向两个角度出发,对数据级及特征级都加入了优化,以达到尽量减小数据不均衡对模型训练的影响,达到收敛。
横向——特征级
kaiming大神在论文 [10] 中提出Focal loss,一方面,数据分布中存在极度不平衡;另一方面,easy example虽然在后期训练过程中损失很低,但是由于数量大,对损失的贡献还是很大导致模型始终向着易学标签方向收敛。
因此,解决方法如图所示,简单直接地在训练中增加难样本权重。
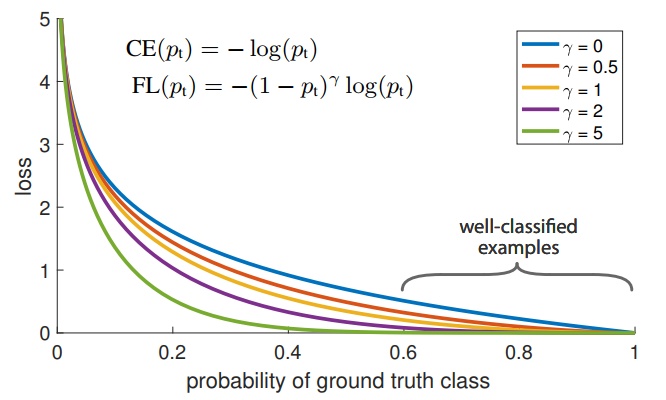
其中,关于超参的选择需要做ablation study。
纵向——数据级
对于数据本身,我们也可以用一种有效的数据扩增方法,有效的提高不平衡数据中弱势标签的频次,通俗来讲,提升标签的存在感,即resampling [3] 。
由于是多标签识别,因此resampling也需要一定的策略:
重复因子设定
标签级:
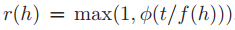
对于每个标签来说,至少重复一次,至多重复右侧函数返回值次
图像级:多个标签重复因子的最大值
resampling函数F选择
uniform
函数结果即n本身
square root
函数结果即为n开根号
上述两点确认之后,还需要一个阈值,即计算标签级重复因子公式中包含的t,表征标签的目标频次。
自测及客户反馈结果可见,上述方法对模型性能的提升,无论是横向还是纵向都有极大的帮助,以下表格展示了在召回相差不多的情况下,性能提升的对比。
| 版本号 | 优化方案 | 精度提升 |
|---|---|---|
| v1.0 | baseline | - |
| v2.0 | baseline + resampling | 10% |
| v2.1 | baseline + resampling + focal loss | 3.2% |
占比小的标签
这部分标签例如眼镜,通常在一个整体画面都比较小,虽然神经网络会学到各个标签之间的一些高级语义关系,但是能力有限,因此这里需要借助目标检测对这类小物体识别做辅助。
由于场景多标签识别是整个项目的重点,目标检测部分作为辅助,简单使用了SSD模型 [12] ,这里不做太多阐述。
先验关系谱
除了深度学习算法层面可以做的优化,从标签的特性来看,在后处理中也可以借助标签之间的多种关系来补足模型没有学尽的语义知识,因此,要使用先验知识构建关系图谱。
这里给出关系图谱的部分示例。
自测及反馈显示效果显著,特别对于一些大类标签(例如运动,因种类繁多而造成特征不统一,网络难以学习得很好)有极强的提高。
整个迭代过程中都能看出,ToB的图像识别项目,需要更加注意和实际场景的结合,其中有很多细节没有展现,也有很多算法尝试没有提及,这里仅展示对算法有效且成功的优化点。一个算法的优化都是以问题分析作为依托的,了解好背景及现状,抓住痛点对症下药,一定是良方。
四、推理
推理是项目的重点,如何给客户输出更佳的预测结果,也是一个需要加入考虑且必不可少的环节。
本文开篇就提到,项目的测评方式很直接,每一类作为单独的类别,计算准召。
由此可见,在项目的迭代过程中,自测集的构建及干净程度对结果尤为重要。
本章假设自测集的干净程度在95%左右,即错误标签+漏标签少于5%,如果没有达到这个标准,先按照二做相应的清洗。
图像多标签的输出有别于单标签,不是简单地输出top1就可以,需要定制化阈值,每个标签进行比对再决策输出结果,这就引出了一个重要的工具:PR曲线。[11]
PR曲线的构造其实是根据测试集中标签所对应的数据推理结果,不断选择梯度阈值而计算所得的结果,如下图所示。(标签名做了脱敏处理)
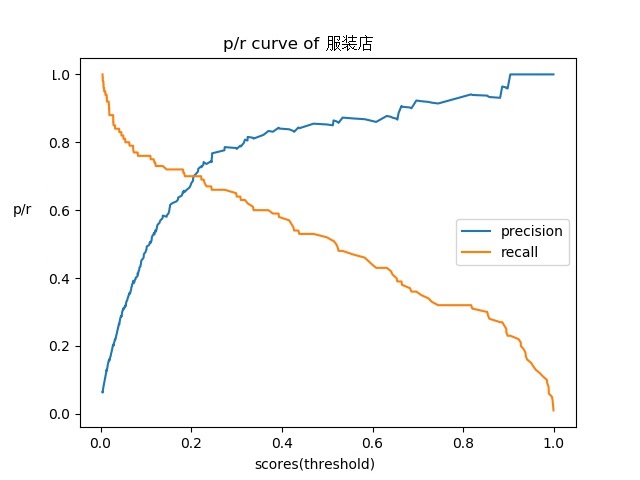
由于是定制化服务,因此选择客户需要的准召对应的阈值即可达到模型的相应性能。例如图中服装店,想要达到准召90/50的标准,选择阈值0.6左右即可。
多种策略相辅相成,最终大大超出客户预期完成交付。(撒花)
五、拓展
一个项目从前期准备到后期交付的过程中,会经历不同角色的转变,也从用户的角度更加理解图像标签能够帮助客户做什么辅助。
角色转变:
产品:和客户沟通,提供标签定义及相似标签分类准则,探讨用户眼中合理的层级关系
数据标注员:整合标签标注标准,亲自标注寻找标注关注点,提高标注速度
算法研究员:在mentor的指导下探索调研最佳方案并训练模型
开发:封装,为客户方开发同学提供部署及相关维护服务
测试:测评指标及和客户沟通验收测评方案
不同的角色,做项目中不受限于算法研究,提升技术能力的同时,锻炼了沟通能力、项目管理能力、项目架构能力等,形成了一定的方法论,成长颇多。
不仅如此,一个项目的广度远不止完成交付,还有极大的空间做扩展:
标签体系扩充构建
标签体系可以由400类逐步扩充,特别是场景及事件等难识别标签类。
结合自有标签(超5000类),扩大标签涵盖维度,为日常生活场景识别提供更好服务。
定制化服务
根据客户的具体需求,加强模型对所需类别的敏感度,提供更好的定制化服务。
参考
[1] The Open Images Dataset V4
[2] Deep Residual Learning for Image Recognition
[3] Exploring the Limits of Weakly Supervised Pretraining
[4] torch.nn.BCEWithLogitsLoss
[5] Learning From Noisy Large-Scale Datasets With Minimal Supervision
[6] Bag of Tricks for Image Classification with Convolutional Neural Networks
[8] Must Know Tips/Tricks in Deep Neural Networks
[9] The Impact of Imbalanced Training Data for Convolutional Neural Networks
[10] Focal Loss for Dense Object Detection