
[paper reading] SimCLR
撰写于 2020-11-24 修改于 2021-07-07 views
[paper reading] SimCLR
PAPER
A Simple Framework for Contrastive Learning of Visual Representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton
REPRESENTATION
What is the task? Why? How?
What
Learning effective visual representations without human supervision is a long-standing problem.
Why
Unlabeled data and labeled data. (理想丰满,现实骨感)
How
- generative
- DBN、AE、GAN
- pixel-level expensive,not necessary for representations learning
- DBN、AE、GAN
- discriminative
- pretext tasks
- rely on heuristics to design,limit the generality
- contrastive learning
- pretext tasks
What is contrastive learning? Why? How?
What & Why
“BERT” in computer vision
good representation -> High-level semantic information guides complex combinatorial logic tasks
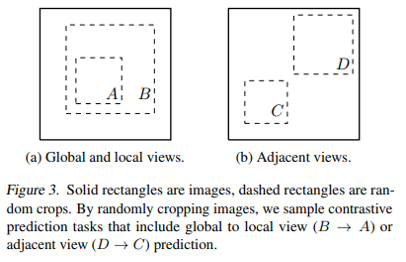
How
如何建立正例和负例,尽可能提升pair能cover的semantic relation
如何定义目标函数,将正例pair与负例pair区分
Score(f(x), f(x+ )) ≫ Score(f(x), f(x- ))
What is SimCLR?
Simple framework
- data augmentations
- a learnable nonlinear transformation
- larger batch sizes and more training steps
Why?
Theory
complexity
avoided by performing simple random cropping (with resizing) of target images
Amount number of experiments
How?
Positive pairs and negative pairs
minibatch of N examples -> 2N data points -> 1: 2(N - 1)
Object function
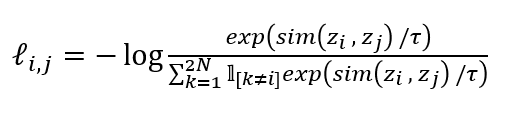
Training with large batch size
Global BN

Performance
数据扩增的重要性、必要性(数据扩增方式选择)
大模型(model size)的重要性、必要性
非线性projection head的重要性、必要性
Normalized cross entropy loss with adjustable temperature works better than alternatives
大batch、长训练的优越性
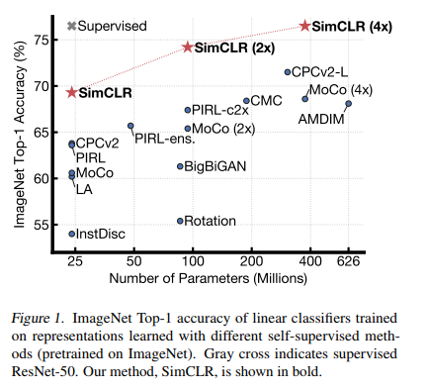
less is more (少即是多)
Q & A
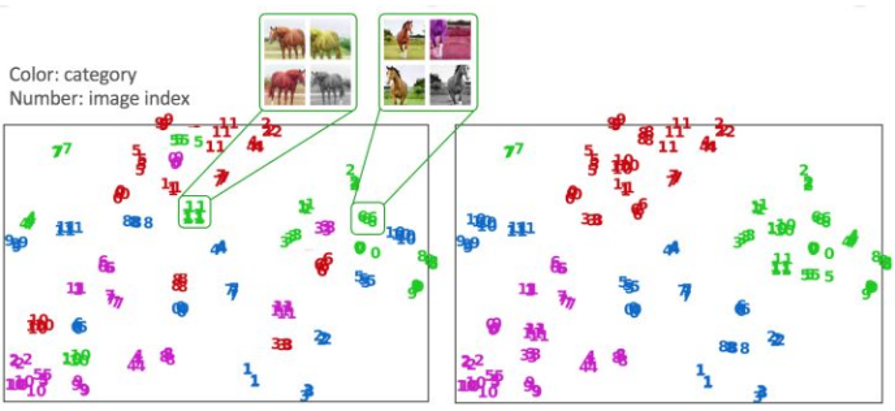
特征空间中的距离远近?类间?样本间?
Bigger model?深度?宽度?